Introduction to Computing for Engineers and Computer Scientists
Finishing OO and on to Machine Learning
Introduction to Computing for Engineers and Computer Scientists
Finishing OO and on to Machine Learning
HW5 Discussion¶
General Comments¶
- (A): OO programming is complex and is very baffling in the beginning, but does enable code reuse and overall program simplification.
- (B): Python's operator overloading and ability to support "mathematic" and other functions for abstract types is one of the language's most powerful features. The concept is simple in scope but complex to understand, however.
- (A) + (B) $\Rightarrow$ HW5: The complexity and subtlety means that HW5 is intellectually very hard but the overall scope is very small.
- We have touched a small subset of Python's OO capabilities and general support for extensibility, both of which are language strengths.
- This assignment is hard. I understand and we will grade accordingly.
- But, many of you are banging your heads against the wall in frustration.
Part 1: Abstract Algebra¶
- Color is a simple example. We will represent color with symbols and a Cayley table.
- $G = {r, g, b, y, m, c},$ where the symbols represent red, green, blue, yellow, magenta, cyan.
- The (silly) Cayley tables is (clearly I was bad at art in kindergarten):
| 
- Representing this as a list of lists would be awkward.
- color_cayley['r']['g'] does not make much sense for lists.
- List iteration is of the form color_cayley[1][7]. There are ways I could do this but it would be awkward.
- color_cayley['r']['g'] looks like a dictionary of dictionaries. I could have done the table this way, but choose a slightly different approach. In my dictionary,
- A pair of symbols is the key, e.g. ('r', 'g')
- The value is the symbol that represents "multiplying" the colors using the group operator.
# This simply keeps me from having to do 'c' over and over.
r,g,b,y,m,c = 'r','g','b','y','m','c'
cayley_colors = {}
cayley_colors.update({(r,r):r, (r,g):y, (r,b):m, (r,y):g, (r,c):b, (r,m):c})
cayley_colors.update({(g,r):y, (g,g):g, (g,b):c, (g,y):r, (g,c):b, (g,m):m})
cayley_colors.update({(b,r):m, (b,g):c, (b,b):b, (b,y):g, (b,c):r, (b,m):y})
cayley_colors.update({(y,r):m, (y,g):r, (y,b):c, (y,y):y, (y,c):g, (y,m):b})
cayley_colors.update({(c,r):g, (c,g):y, (c,b):m, (c,y):b, (c,c):c, (c,m):r})
cayley_colors.update({(m,r):c, (m,g):y, (m,b):r, (m,y):g, (m,b):c, (m,m):m})
print("If if got this right, with so little coffee, it is a miracle.")
cayley_colors
- I can define a new subclass of BaseCayleyGroup
class BaseCayleyGroup(object):
pass
class CayleyColorsGroup(BaseCayleyGroup):
__symbols = {'r', 'g', 'b', 'y', 'c', 'm'} # Attribute of class -- group symbols
__table = None # Attribute of class -- Cayley Table for class.
def __init__(self, v):
# Not strictly the correct approach. Should probably return an error, but OK.
self.__value = v
# This is a property of the class. I could have done this outside of the class
# but I that freaks me out for no good reason.
if CayleyColorsGroup.__table is None:
r,g,b,y,m,c = 'r','g','b','y','m','c'
cayley_colors = {}
cayley_colors.update({(r,r):r, (r,g):y, (r,b):m, (r,y):g, (r,c):b, (r,m):c})
cayley_colors.update({(g,r):y, (g,g):g, (g,b):c, (g,y):r, (g,c):b, (g,m):m})
cayley_colors.update({(b,r):m, (b,g):c, (b,b):b, (b,y):g, (b,c):r, (b,m):y})
cayley_colors.update({(y,r):m, (y,g):r, (y,b):c, (y,y):y, (y,c):g, (y,m):b})
cayley_colors.update({(c,r):g, (c,g):y, (c,b):m, (c,y):b, (c,c):c, (c,m):r})
cayley_colors.update({(m,r):c, (m,g):y, (m,b):r, (m,y):g, (m,b):c, (m,m):m})
CayleyColorsGroup.__table = cayley_colors
@classmethod # Method on class. HINT: Base class calls.
def get_cayley_table(cls):
return CayleyColorsGroup.__table
# Method on instance. HINT: base class calls.
def get_value(self):
return self.__value
c1 = CayleyColorsGroup('r')
c2 = CayleyColorsGroup('r')
c3 = CayleyColorsGroup('g')
print('(c1 == c2) =', c1 == c2)
print('(c1 == c3) =', c1 == c3)
- What did that test tell me? The
==operator works $\Rightarrow$- Some class implements
__eq__() CayleyColorsGroupdoes not implement__eq__()- So, the method MUST be in
BaseCayleyGroup. - And I have you two hints:
- Group elements are equals if the symbol is the same.
BaseCayleyGroupcallsCayleyColorsGroup.get_value()
- Some class implements
c4 = c1*c2
print(c4)
- What did that test tell me? The
*operator works $\Rightarrow$- Some class implements
__mul__() CayleyColorsGroupdoes not implement__mul__()- So, the method MUST be in
BaseCayleyGroup. - And I gave you three hints:
- You need the Cayley Table to lookup the answer.
- I implemented the CayleyTable as a dictionary.
BaseCayleyGroupcallsCayleyColorsGroup.get_cayley_table()
- Some class implements
c5 = c4.get_cayley_table()[('r','g')]
c5
- You know getting the table returns a dictionary. You could have tried the method. What the heck, right?
- The answer was not quote right, because we want a member of the group. So,
__mul__()must be something like
c6 = CayleyColorsGroup('r')
c7 = CayleyColorsGroup('g')
print("If I have ", c6, 'and', c7, 'then', c6, '*', c7, '=')
c8 = CayleyColorsGroup(c6.get_cayley_table()[c6.get_value(), c7.get_value()])
print(c8)
- So what have we concluded?
BaseCayleyGroupmust implement__eq__()and__mul__()- It must be calling
get_value()andget_cayley_table()on itself, and getting the child implementation. - Don did something weird with the
__str__()inBaseCayleyTableto do the printing, but he did not ask us to do that.
- If you can do this homework, you will have mastered the two core concepts in OO:
- Simplifying application development by putting come functions in base classes, and inheriting in subclasses.
- Extending and completing base classes and frameworks by implementing/overriding base methods.
- There is one more trick.
x = BaseCayleyGroup(anything)must raise an exception.
All told, you write about 8 statements in the base class, and know you have to implement
__init__()__eq__()__str__()__(Optional).__mul__()
You have implemented simple classes and demonstrated Abstraction, Encapsulation and Inheritance.
Part 2: Matrices¶
- I showed you what a matrix looks like.
tt = MySparseMatrix(int, 2, 2)
tt.set(0,0,11)
tt.set(0,1,5)
tt.set(1,0,2)
print(tt.get(0,1))
print("tt = ", tt)- Produces
5 tt = 2 X 2 matrix of type <class 'int'>: 11,5 2,0
- Well, an empty 2x2 matrix is something like
m = [[0,0],[0,0]]
print(m)
- So, I must have some kind of
__str__()method to print slightly differently.
set(0, 0, 11)must map to something likem[0][0]but that only works if I have already set up the lists with default values. Otherwise, I get undefined.
- And I know that I must do something to create values even if not set because the entry 1,1 is set to 0.
- But, the matrix is of any type. I pass in the type. How do I make default values of a type in a general way?
- Hint:
x = complex
print(x())
- That is enough hints for
MyMatrix.Equality and addition are obvious once you have figured out the matrix basic initialization, get and set.
- What about sparse matrices? You can only "store" values that are set.
- Think about what that means. The caller will give you
(i,j)and you have to return:- The value if it exists.
- The default for the type, otherwise.
- Well, the Cayley table implementation shows you how to male
(i,j)to a value. - And you had to solve the default class instance for MyMatrix.
- Matrix addition and equality require get() and set(), and you know how to override a method.
Print Statements versus Logging¶
- You have seen that the print statements can be helpful, but can also be overwhelming.
- At different stages of development, I need to turn some on and some off. Just embedding print statements and commenting out is tedious.
- I would also like to:
- Selectively print some statements for comfort, debugging, etc.
- Print messages when something critical happens.
- Write a lot of information to a (CSV) file for later analysis.
- Instead of printing explicitly, I will have the code emit log events when something happens. Configurable event listeners will determine
- What messages go to the console for debugging, monitoring, etc.
- What data goes to a file for subsequent analysis.
- Most environments, including Python, have the concept of a logger.
- Instead of adding, removing, commenting out, etc. "print()" statements, I should
- instrument my code with log statements
- And then use
- Handlers
- Filters
- To determine which information goes where.
import logging
file_level = logging.DEBUG console_level = logging.ERROR
# create logger with logger to show to the class.
# An application can have several loggers.
logger = logging.getLogger('e1006_application')
# The logger's level is DEBUG.
logger.setLevel(logging.DEBUG)
# create file handler which logs even debug messages
fh = logging.FileHandler('demo.log')
fh.setLevel(logging.DEBUG)
# create console handler with a higher log level
ch = logging.StreamHandler()
ch.setLevel(logging.ERROR)
# create formatter and add it to the handlers
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# add the handlers to the logger
logger.addHandler(fh)
logger.addHandler(ch)
logger.debug("***** Starting a test run *******")
logger.info('Creating an info message.')
logger.debug("Creating a debug message")
logger.warning("Creating a warning message.")
logger.error("Creating an ERROR message.")
logger.error("Creating another ERROR message.!")
- What does the log file look like?
with open("demo.log", "r") as log_file:
for line in log_file:
print(line)
# I can change the level of the logger.
ch.setLevel(logging.WARNING)
logger.debug("***** Starting a test run *******")
logger.info('Creating an info message.')
logger.debug("Creating a debug message")
logger.warning("Creating a warning message.")
logger.error("Creating an ERROR message.")
logger.error("Creating another ERROR message.!")
- An application can also define it's own logging level. The default levels are:
| Level | Numeric value |
|---|---|
| CRITICAL | 50 |
| ERROR | 40 |
| WARNING | 30 |
| INFO | 20 |
| DEBUG | 10 |
| NOTSET | 0 |
- And the file again, ...
with open("demo.log", "r") as log_file:
for line in log_file:
print(line)
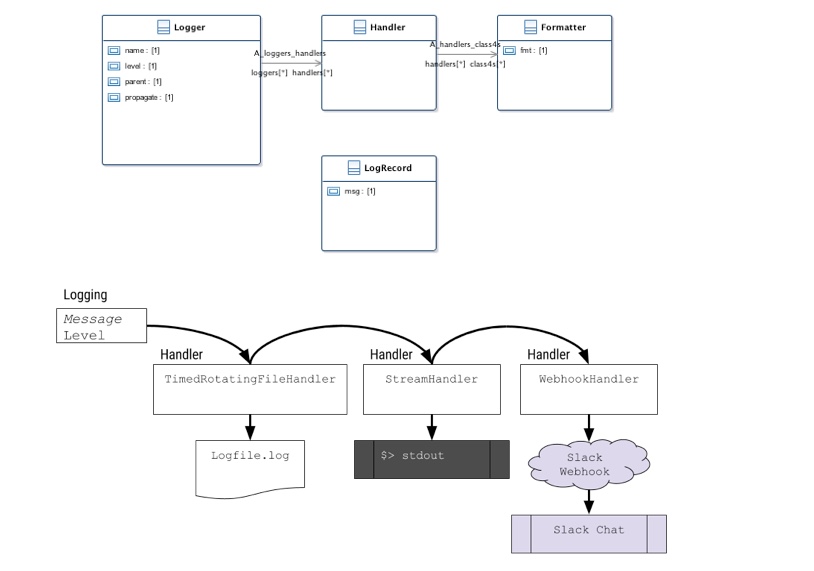 |
|---|
| Logging Conceptual Model |
- In practice: In the product I have been building:
- We write very detailed log messages for auditing, problem determination, etc.
- We selectively send critical messages to a Slack channel to immediately notify someone of the team that there is a problem.
 |
|---|
| Slack Critical Message Channel |
 |
|---|
| Full Log Stream |
Summary:
- There is no action or to do for you. This is FYI.
- I put print statements in my example code to help with teaching and explanation.
- I want to make sure that you understand this is not a "real" approach to the function.
The Strange Island¶
- We have four lectures left, including this one. I need to move on from OO.
- We implemented
- Initialization
- Animation
- A class model for organisms, animals, plants, predators and prey.
- The ability to move around and die of old age.
- We need to implement starvation, reproduction and eating. This occurs when two things are at the same (i,j) location. All we need to do is implement a function that:
- Looks at every (i,j) location.
- If there is more than one thing
- (moose, moose) $\rightarrow$ new moose if long enough since last birth.
- (wolf, wolf) $\rightarrow$ new wolf if long enough since last birth
- (wolf, moose) or (moose, wolf) $\rightarrow$ fed wolf and dead moose.
- (plant, moose) or (moose, plant) $\rightarrow$ fed moose and dead plant.
- We also need to support plants spreading.
- These are relatively straightforward extensions to what we have done, but I want to move on to some cool things. So,
- I will complete and publish the code.
- Schedule an optional recitation where I walk through and we discuss the details for the few of you who are interested.
- Extra-credit 3 will be examining my code and suggesting, in writing 3 changes that would improve the solution that I hacked together.
Moneyball!¶
Lecture 1 $-$ Reminder: Why Python?¶
"The Case For Python in Scientific Computing"
- Interoperability with other languages: Complex science and engineering problems interact with preexisting systems and devices that use a diverse set of languages, interfaces, data models, etc.
- Reusable tools and libraries:_ All languages come with built in tools (reusable sets of programs). Python by far has the best set of resuable tools and libraries. "If you have a problem to solve, you can most likely find a library to help and it's probably on github!"
- Open source: Enables independent extensions and evolution, although this is true of many languages.
 |
|---|
| Python and Scientific/Engineering |
- For engineers and applied scientists, learning the Python language is a means to an end.
- The end is the rich and expanding portfolio of tools, frameworks, utilities.
Introduction and Overview¶
- "Moneyball: The Art of Winning an Unfair Game is a book by Michael Lewis, published in 2003, about the Oakland Athletics baseball team and its general manager Billy Beane. Its focus is the team's analytical, evidence-based, sabermetric approach to assembling a competitive baseball team, despite Oakland's disadvantaged revenue situation."
- "The central premise of Moneyball is that the collective wisdom of baseball insiders (including players, managers, coaches, scouts, and the front office) over the past century is subjective and often flawed. Statistics such as stolen bases, runs batted in, and batting average, typically used to gauge players, are relics of a 19th-century view of the game and the statistics available at that time. Before sabermetrics was introduced to baseball, teams were dependent on the skills of their scouts to find and evaluate players. Scouts are those who are experienced in the sport, usually having been involved as players or coaches. The book argues that the Oakland A's' front office took advantage of more analytical gauges of player performance to field a team that could better compete against richer competitors in Major League Baseball (MLB)"
- We will do very simple versions of the concept to get a feel for data analytics, numerical libraries and machine learning using Python.
- What data do we have about teams?
 |
|---|
| Team Performance Data |
- What do we know about players?
- Batting is offensive statistics, e.g. hits, home runs, etc.
- Fielding is how they handle hit balls, e.g. attempts, errors.
- Pitching is the opposite of batting, e.g. how often does the pitcher give up a hit?
- What positions can/do players play?
- Salaries.
- Positions
 |
|---|
| Player Positions |
- Offensive (Batting)
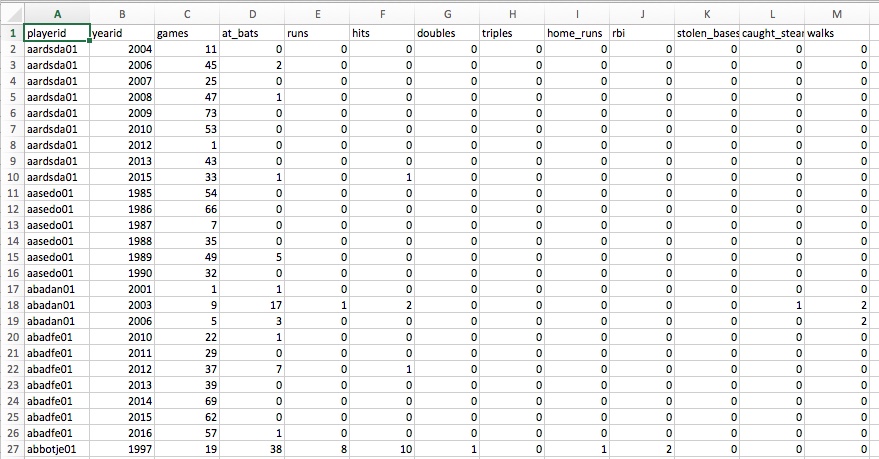 |
|---|
| Player Batting Info |
- Pitching
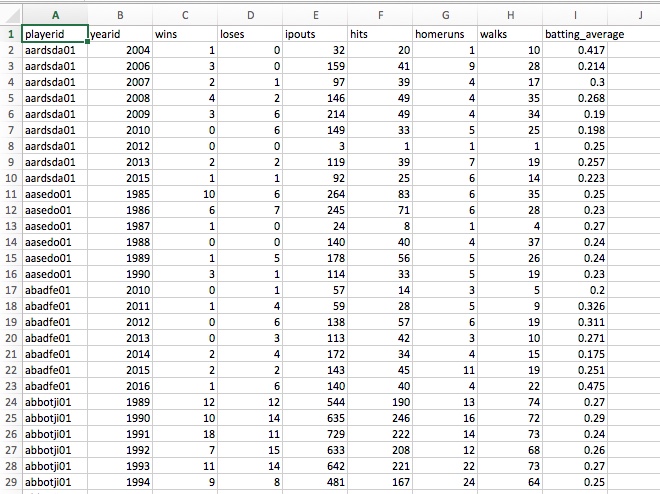 |
|---|
| Player Pitching Info |
- Fielding
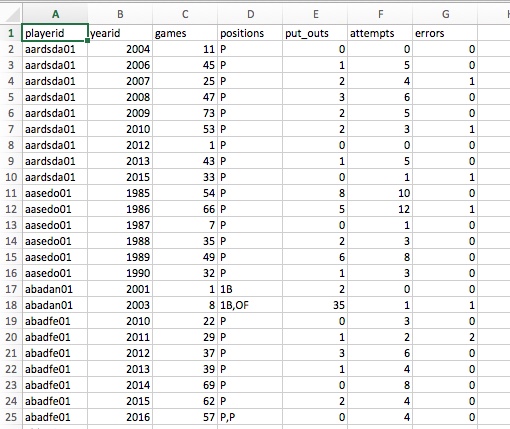 |
|---|
| Player Fielding Info |
- Salaries
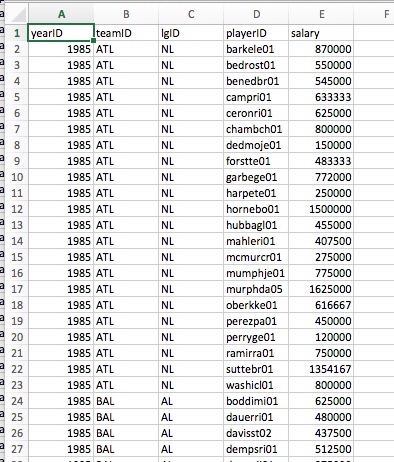 |
|---|
| Player Salary Info |
Read Data¶
import pandas as pd
df = pd.read_csv("../Data/teaminfo.csv")
df.tail(20)
- What did we just do?
- Read a CSV into a Pandas DataFrame
- Examined the last 20 rows (actually produced a new DataFrame containing) the last 20 rows of the original DataFrame.
Let's Visualize and Analyze¶
- Cool thing 1: Histogram Wins
import matplotlib.pyplot as plt
plt.ioff()
# Make a figure/subplot
plt.figure(figsize=(10,8))
# Histogram wins into 20 buckets
n, bins, p = plt.hist(df['wins'], 20, label="Histogram of Wins")
# Compute the mean number of wins and plot as a line.
mu = df['wins'].mean()
min = df['wins'].min()
max = df['wins'].max()
l = plt.plot([min,max], [mu,mu], label="Average Wins")
plt.legend()
plt.show()
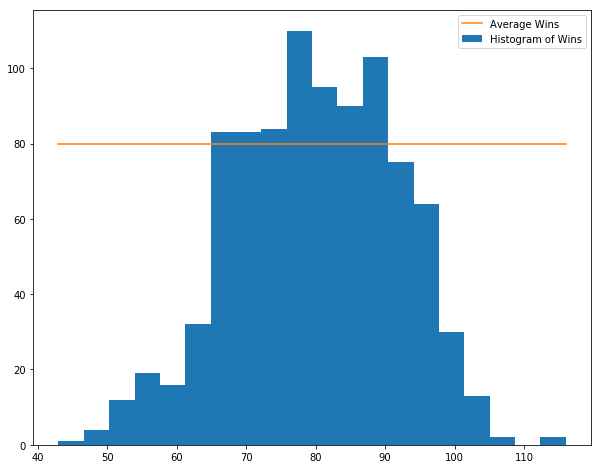
- Cool thing 2: Scatter Plot wins as a function of homeruns.
# Make a new DataFrame with just the columns we want.
w_v_hr = pd.DataFrame(df[['home_runs','wins']])
# Make a new figure and set the size.
plt.figure(figsize=(10,8))
# Produce a scatter plot. The point color is green and the marker is a triangle.
plt.scatter(w_v_hr['home_runs'], w_v_hr['wins'], color="g", marker="^")
# Set some labels, font sizes and colors.
plt.xlabel("Homeruns", fontsize=20, color="r")
plt.ylabel("Wins", fontsize=20, color="b")
# Show the figure.
plt.show()

- What is the correlation between HRs and wins?
w_v_hr.corr()
HOW HOW TO INTERPRET A CORRELATION COEFFICIENT R
In statistics, the correlation coefficient r measures the strength and direction of a linear relationship between two variables on a scatterplot. The value of r is always between +1 and –1. To interpret its value, see which of the following values your correlation r is closest to:
- Exactly $–1$: A perfect downhill (negative) linear relationship
- $–0.70$: A strong downhill (negative) linear relationship
- $–0.50$: A moderate downhill (negative) relationship
- $-0.30$: A weak downhill (negative) linear relationship
- $0$: No linear relationship
- $+0.30$: A weak uphill (positive) linear relationship
- $+0.50$: A moderate uphill (positive) relationship
- $0.70$: A strong uphill (positive) linear relationship
- Exactly $+1$ A perfect uphill (positive) linear relationship
- Correlations gone wild.
df.corr()
- Including year in a correlation between metrics does not make sense.
df2 = df.drop(['year'], axis=1)
df2.corr()
How Much Data do We Have?¶
print("(rows, columns) for teams is = ", df.shape)
batting_df = pd.read_csv("../Data/playerbatting.csv")
pitching_df = pd.read_csv("../Data/playerpitching.csv")
fielding_df = pd.read_csv("../Data/playerfielding.csv")
salary_df = pd.read_csv("../Data/playersalary.csv")
print("(rows, columns) for batting is = ", batting_df.shape)
print("(rows, columns) for pitching is = ", pitching_df.shape)
print("(rows, columns) for fielding is = ", fielding_df.shape)
print("(rows, columns) for salary is = ", salary_df.shape)
all_dfs = [df, batting_df, pitching_df, fielding_df, salary_df]
total_cells = sum([x.shape[0]*x.shape[1] for x in all_dfs])
print("total number of cells is = ", total_cells)
Let's Take a Step Back¶
We have at least 3 tasks:
- Figure out the relationships between team performance metrics (e.g HRs, ERA) and a team's wins. What metrics do we want to optimize?
- Given a set of players, estimate the team's performance if the team has the players.
- Find the cost optimal team(s)
This will involve:
- Data Munging.
- Cleaning and shaping.
- Data Exploration/Visualization.
- Learning.
- Optimization.
But first, least learn a little about Pandas and PyPlot, which we need for all 5 tasks.
Pandas¶
Overview¶
- There is a very good tutorial and set of recipes for common scenarios as https://pandas.pydata.org/pandas-docs/stable/tutorials.html.
- This section will go through some of the material in the context of our data and business problem -- Moneyball.
((https://en.wikipedia.org/wiki/Pandas_(software)))
"pandas is a software library written for the Python programming language for data manipulation and analysis. In particular, it offers data structures and operations for manipulating numerical tables and time series. It is free software released under the three-clause BSD license.[2] The name is derived from the term "panel data", an econometrics term for data sets that include both time-series and cross-sectional data"
Library features:
- DataFrame object for data manipulation with integrated indexing.
- Tools for reading and writing data between in-memory data structures and different file formats.
- Data alignment and integrated handling of missing data.
- Reshaping and pivoting of data sets.
- Label-based slicing, fancy indexing, and subsetting of large data sets.
- Data structure column insertion and deletion.
- Group by engine allowing split-apply-combine operations on data sets.
- Data set merging and joining.
- Hierarchical axis indexing to work with high-dimensional data in a lower-dimensional data structure.
- Time series-functionality: Date range generation[4] and frequency conversion, moving window statistics, moving window linear regressions, date shifting and lagging.
- The library is highly optimized for performance, ..."
Core Data Structures¶
| Data Structure | Dimensions | Description |
|---|---|---|
| Series | 1 | 1D labeled homogeneous array, sizeimmutable. |
| Data Frames | 2 | General 2D labeled, size-mutable tabular structure with potentially heterogeneously typed columns. |
| Panel | 3 | General 3D labeled, size-mutable array. |
| Pandas Data Structures |
- We will focus on DataFrames.
 |
|---|
| DataFrame |
- Out data is tabular and naturally maps to DataFrames. For example,
batting_df.tail(30)
df.tail(20)
Basic Operations¶
teams_sorted_by_wins = df.sort_values(by=['wins'])
teams_sorted_by_wins.head(10)
teams_sorted_by_wins = df.sort_values(by=['wins', 'teamid'], ascending=False)
teams_sorted_by_wins.head(10)
Filter¶
teams_sorted_by_winsis already sorted. I want ONLY National League Teams for years greater than or equal to 2000, and the team is either BOS or NYY.
f1 =(df['year'] >= 2000)
f2 = (df['teamid'].isin(['BOS','NYA']))
interesting_teams = teams_sorted_by_wins[f1 & f2]
interesting_teams.head(20)
- Teams that won 20 or more games than they lost but did not finish 1st.
unhappy_teams = df[(df['wins'] > (df['loses'] + 20)) & (df['rank'] > 1)]
unhappy_teams.sort_values(by=['wins'], ascending=False).head(10)
Subset Columns (Projection)¶
just_team_year_and_wins = df[['teamid', 'year', 'wins']]
just_team_year_and_wins.head(10)
batting_df.head(10)
salary_df.head(10)
- The column names are different and I need to modify.
salary_df2 = pd.read_csv('../Data/playersalary.csv')
salary_df2.columns = salary_df2.columns.str.lower()
salary_df2.head(10)
batting_df2 = batting_df.set_index(['playerid', 'yearid'])
salary_df2 = salary_df2.set_index(['playerid', 'yearid'])
batting_and_salary = batting_df2.join(salary_df2)
batting_and_salary[['home_runs','salary']].head(10)
What are these JOIN and Index of which you Speak?¶
Index
"A (...) index is a data structure that improves the speed of data retrieval operations on a (...) table at the cost of additional (...) storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a (...) table every time a (...) table is accessed. Indexes can be created using one or more columns of a (...) table, providing the basis for both rapid random lookups and efficient access of ordered records." (https://en.wikipedia.org/wiki/Database_index)
 |
|---|
| Binary Tree Index |
- There are many types of index.
- Simplistically, if I want to find all rows with a given (playerid, yearid) a 1,000,000 row table
- Scanning each row is O(1,000,000) comparisons
- Using a binary search index is O(20) comparisons, or exponentially faster.
JOIN
- "An SQL join clause combines columns from one or more tables in a relational database. It creates a set that can be saved as a table or used as it is. A JOIN is a means for combining columns from one (self-join) or more tables by using values common to each." (https://en.wikipedia.org/wiki/Join_(SQL))
- There are many, many kinds of JOIN. Over simplistically
- Build a new table (DataFrame)
- Each row contains all columns from DataFrame A and all columns from DataFrame B.
- Only include rows where A.x = B.y
 |
|---|
| Natural JOIN Example |
{kind=link}
- We are going to need JOIN because data from several tables characterizes a player's performance
- Batting (offense)
- Fielding (defense)
- Pitching
- Salary
Coming up Next Lecture¶
- A little more Pandas to finalize what we need to analyze performance data.
- Multi-layer Perceptron neural network for determining how a team's statistics define wins.
- This is based on a formal, scientific, engineering solution to a problem baseball historically solved with intuition.
Formal Definition:
- A vector of metrics $\vec{x}$ summarizes a team's performance capabilities, e.g. batting average, HRs, etc.
- A similar vector $\vec{p}$ summarizes the performance contribution of a player to the team $T.$
- Let $i$ be the subscript notation for the i-th metric. If $f_i$ is some aggregation function, e.g. sum, average, then
\begin{equation} x_i = f_i(p_i), \forall p \in T. \end{equation}
- $S(p)$ can denote player $p$ salary. This yields two constraints
- C1: $ \#(T) \leq 25$ (approximating the maximum number of allowed players per team)
- C2: $\sum_{p \in T}{S(p)} \leq B(T),$ team $T$ budget.
- If
- $W(\vec{x})$ is the number of wins per season as a function of $\vec{x} \in X.$
- $P(\vec{x}) \rightarrow [0,1]$ is the probability of winning the World Series for $\vec{x} \in X.$
- We want to pick the team of players $T$ such that we
- $Max(W(\vec{x}))$ or $Max(P(\vec{x}))$
- With minimal $\sum{S(p)}$
- Subject to C1 and C2.
- This boils down to two tasks:
- Learning the relationship between $\vec{x}$ and wins (or winning world series).
- Finding the price-optimal set of players. We are trying to build an artificial intelligence engine that replaces general managers for picking players.
Next Task
We will define and train a Multi-Layer Perceptron!
 |
|---|
| Neurons and Perceptrons |