Introduction to Computing for Engineers and Computer Scientists
HW2, Algorithms, Some Libraries
Introduction to Computing for Engineers and Computer Scientists
HW2, Algorithms, Some Libraries
Questions, Comments¶
Questions from Class¶
- This question will become tricky when we start using classes. (Punch and Enbody, Chpt. 11)
- Any object (variable or literal) we have seen so far is of a simple type, e.g. float, int, ...
- Classes allow programmer defined types, and an object can simultaneously have several types.
Short Answer¶
- For now, you can use the built in function isinstance().
In [2]:
isinstance(1,int)
Out[2]:
In [3]:
isinstance(3.2,float)
Out[3]:
In [5]:
isinstance(3.2,int)
Out[5]:
An Example
In [39]:
import matplotlib.pyplot as plt
def add_to_plot(x,y):
result = False
if (isinstance(x,int) or isinstance(x,float)) and \
(isinstance(y,int) or isinstance(y,float)):
plt.plot(x,y,"ro")
result = True
return result
In [41]:
x = 3
y = 4
if add_to_plot(x,y):
print("Plotted ",x,",",y)
else:
print("Plotting ",x,",",y,"failed!")
x = 2
y = 9.2
if add_to_plot(x,y):
print("Plotted ",x,",",y)
else:
print("Plotting ",x,",",y,"failed!")
x = 1.3
y = 7
if add_to_plot(x,y):
print("Plotted ",x,",",y)
else:
print("Plotting ",x,",",y,"failed!")
x = 'c'
y = 7
if add_to_plot(x,y):
print("Plotted ",x,",",y)
else:
print("Plotting ",x,",",y,"failed!")
plt.show()

Longer Answer -- Duck Typing¶
- Duck Typing? I am not kidding.
- Duck Typing: "Duck typing is concerned with establishing the suitability of an object for some purpose, using the principle, "If it walks like a duck and it quacks like a duck, then it must be a duck." With normal typing, suitability is assumed to be determined by an object's type only. In duck typing, an object's suitability is determined by the presence of certain methods and properties (with appropriate meaning), rather than the actual type of the object."
- What does this mean? Try to use it like a duck, and if explodes, it was not a duck. I am not kidding.
In [45]:
import matplotlib.pyplot as plt
try:
x,y = 1.1, 3
plt.plot(x,y,"ro")
x,y = 3.2, 5
plt.plot(x,y,"ro")
x,y = 'a','yellow'
plt.plot(x,y,"ro")
plt.show()
except ValueError as ve:
print("Got value error = ",ve)
finally:
print("Either ",x,"or",y,"was not a duck.")
Python Features¶
 |
|---|
| Python Features |
- Every (almost) every feature in Python exists in other languages.
- We covered this course's choice of Python in the 1st lecture.
- The example of
a,b = b,ais a specific case offa,b = <expresion>- This syntax and capability is unusual.
- Some other languages support it, e.g. Lua
- Languages implement statements by parsing and code generation.
- The basic syntax is
LHS = <expression> - Simplistically, the steps in the evaluation of x = 1 + 2 are
- Evaluate the expression 1 + 2 and create a new object with the value.
- Change x to reference the new object.
- Delete/release the previous object x referenced, if not other variable references it.
- The generated code evaluates the
<expression>and produces an object, and then changes the variable to reference the object.
- The basic syntax is
- This is what Python does but extends to
LHS1, LHS2, LHS2 = <expression1>, <expression2>, <expression3>
- The generated code evaluates all of the expressions and creates the result objects, _and then has the LHS reference the result expressions.
- Just like
a + b,ais an expression.
In [46]:
a = 3
# a is an expression. Evaluate a.
a
Out[46]:
- Overly simplistically, for
a,b = b,aPython parses and produces the following code- Evaluate the expression
band produce a new objecto1with the value. - Evaluate the expression
aand produce a new objecto2with the value. - Change
ato referenceo1 - Change
bto referenceo2
- Evaluate the expression
- Is this syntax and feature useful? Some people argue "yes" and some people argue "no."
- What do I think? Well,
- I am old $\Rightarrow$ I think all new things are a bad idea.
- I am from rural New England $\Rightarrow$ I am cranky and dislike everything.
- My ancestry is Scottish $\Rightarrow$ I am cranky and dislike everything.
- I am not entirely sure computers are not a bad idea.
- Use the feature if you want. Avoid it if you want.
- The feature most commonly appears in function returns.
In [47]:
# Multiple return example
def three_powers(x):
r1 = x**2
r2 = x**3
r3 = x**3
return r1, r2, r3
# More "traditional" multiple return approach
def another_three_powers(x):
r1 = x**2
r2 = x**3
r3 = x**3
return [r1, r2, r3]
print("Multiple returns = ", three_powers(2))
print("Cranky, old guy multiple returns = ", another_three_powers(2))
- Hmm. I did not expect the parentheses.
In [48]:
a = 1
b = 2
a,b
Out[48]:
In [49]:
x = 3
y = 4
(x , y) = (y, x)
y,x
Out[49]:
- If you decide not to use the multiple assignment syntax,
- You need to be aware of it because
- You may use code or a library that someone else wrote, and they like multiple returns.
Deconstructing HW2¶
Geometric Brownian Motion¶
Explanation¶
- Investopedia (Yes, that is really a thing) has a good explanation of Monet Carlo simulation of stock price evolution.
The formula \begin{equation} S_t = S_{t-1} * (1 + \mu\delta t + \sigma\phi \sqrt{\delta t}) \end{equation}
Is the same as \begin{equation} (S_t -S_{t-1}) = \Delta S = S_{t-1}(\mu\delta t + \sigma\phi \sqrt{\delta t})) \end{equation}
 |
|---|
| Geometric Brownian Motion |
Motivation¶
- Why am I assigning this part as homework?
- I will give you a few formulas for computing $S_t$ from $S_{t-1}$ and parameters, e.g $\mu, $ $\sigma $, $\phi$, ... This will give you practice
- Using variables and operators to compute new values.
- Writing simple functions that accept parameters, validate input and return values.
- Also, remember the goals I stated for the course. One was "Make sure you have cool sounding things to put on resume and talk about in interviews." You will be able to say, "One of my homeworks was using a REST API to retrieve historical stock information. I did very simple statical analysis to estimate drift and volatility parameters for a Monte Carlo simulation that used Geometric Brownian Motion to predict stock return and risk."
- That sounds cool to me.
Example that Shows You Something Similar to Your Assignment¶
- In Economic Equilibrium," there are resources and prices.
- For a specific resource R there are supply and demand functions,
- Demand = $D(p)$
- Supply = $S(p)$
- Let's assume that the supply is fixed and not a function of price.
- We set a price $p_0$ and compute $D(p_0).$ If $D(p_0) = S$, we found the equilibrium price.
- If $D(p_0) \neq S,$ we must compute a new price $D(p_1)$ and try again, and keeping iterating. This is called a tatonnement process.
- What should the next price be? A simple formula, which the "New Jersey Car Trunk Guy" will check for me is,
\begin{equation} p_i = p_{i-1} * {{D(p_{i-1}) - S} \over S} \end{equation}
- A modified implementation is a Walrasian Auction
- The tatonnment function is
In [ ]:
# Given a price p, demand at price p and supply at price p,
# compute the next proposed price.
def new_price(p, d, s):
result = p * (d - s)/s
return result
- You will do some similar functions for GBM. I will describe the functions and parameters and you will implement with a function, operators and variables.
- You can now also mention economic equilibrium, tatonnment processes, and Walrasian Auctions in your interviews. You're welcome.
In [61]:
import pandas as pd
def read_stock_data(ticker):
file_name = "../Data/" + ticker + ".csv"
print("File to read = ", file_name)
df = df = pd.read_csv(file_name)
return df
def compute_average(close_prices):
no_of_entries = len(close_prices)
total = 0
for i in range(0,no_of_entries):
total = total + close_prices[i]
result = total / no_of_entries
return result
# Note: Testing the function with a small enough data set
# to manually, visually compare to CSV file. Actual simulation
# will use much large files.
aapl_df = read_stock_data("AAPL")
print("\n\nAll data = \n", df)
close_prices = df['Adj Close']
print('\n\n Close prices = \n', close_prices)
# Note: Testing on small enough data array to
# manually check correctness.
test = [1, 10, 100]
avg = compute_average(test)
print("test average = ", avg)
Motivation¶
- You basically need to produce a function similar to compute_average(data), but this function must compute
- The average, relative change from entry to entry.
- The variance of the change.
- More practice with math and operators.
- Practice with repetition, loops, etc.
- You can start adding statistical analysis of data using Pandas Dataframes to your resume.
Observations¶
- We are learning the software engineering discipline of decomposition.
- We decompose the problem into a set of smaller, simpler, individuall testable steps.
- This is also know as "breaking it down Barney Style."
- But, there are some deficiencies in the simple examples that you will need to fix, e.g. errors, bad parameters, etc. Your code should handle "gracefully" instead of just failing.
Simple Project¶
Introduction¶
- People do not understand that sequences of random events have surprisingly long streaks that appear non-random. You hear phrases like,
- "He's in a slump."
- "He's due."
- "He's dialed in. He has a hot hand."
- These are versions of the Gambler's Fallacy and the Hot Hand Fallacy.
- We are going to do a simple project that analyzes the concept using simulation. This will
- Give more practice and incremental understanding of programming and Python.
- Provide a template for how to execute the HW2 project.
- Introduce discussion of algorithms.
- Incrementally introduce some new programming concepts.
- We will do this in the context of baseball batting.
- A player has a batting average, which is the probability to getting a hit per at-bat.
- If a player goes N at-bats without a hit, people will say the player is "in a slump."
- Estimate the probability of a player going at least N at bats without a hit once per season.
What Do We Need to Do?¶
 |
|---|
| Breaking it Down Barney Style |
Decision Making Process
- Analyze the higher headquarter's order and commander's intent. (Done)
- Initial intelligence preparation of the battlefield.(Done)
- Determine specified, implied and essential tasks.
- ... ...
Tasks
- Simulate an individual at-bat.
- Simulate a season of at-bats.
- Determine streaks within a season, lengths and number of streaks.
- Simulate multiple seasons to get average behavior for a season.
- Analyze results.
Simulate and Individual At-Bat¶
- We know the batting average ($BA$). How do we simulate a random at-bat? Ideas?
- Well, we need to generate random numbers.
- Generate a random number $x$ on $[0,1)$
- if $x <= BA,$ it is a hit. Basically, we are simulating a biased coin. We want "heads" with probability $BA$ and tails with probability $(1 - BA).$
simulator_core.biased_coin
In [62]:
# This code goes in a module/package of reusable functions.
# Import the pseudo-random number generation functions
import random
# This function's parameter is an float in the
# range [0,1]. This represents the probability of
# an event occuring. The function asssumes uniform
# distribution. The function "flips the biased coin"
# and returns 0 or 1 of the event occurs.
def biased_coin(probability):
random_value = random.random()
if random_value <= probability:
return 1
else:
return 0
/tests/unit_test_coin
In [69]:
# import simulator_core
# This code goes in a module/package that unit tests
# reusable functions and modules.
# Simple test of the coin flipper.
def test_flipper():
total = 0
prob = 0.333
count = 100000
for i in range(0,count):
#total = total + sc.random_event(0.333)
total = total + biased_coin(0.333)
avg = total / count
print("test_flipper: result = ", avg,", expectation = ", prob, " flips = ", count)
test_flipper()
A Project¶
- We want to structure our overall set of code so that
- It is easy to use, understand and modify.
- We can reuse and extend in other "projects."
- Multiple people can work on the code and material.
- Other people and teams can reuse our innovations.
- A project is the overall set of activities for building a software solution. Projects include plans, communication tools, organization structure, ...
- A repository is the most basic element of GitHub. They're easiest to imagine as a project's folder. A repository contains all of the project files (including documentation), and stores each file's revision history. Repositories can have multiple collaborators and can be either public or private.
- We will initial do a lightweight project structure and may evolve to a more complete model.
- Unlike what we have previously done, our solution is going to
- Have a directory structure.
- Multiple files in multiple directories.
- Produce one or more reusable Python modules.
- Unlike what we have previously done, our solution is going to
 |
|---|
| Some Common Project Structures ] |
- We will have the following project structure.
 |
|---|
| Initial Project Structure ] |
Simulate a Sequence of At-Bats¶
- This is just multiple iterations of flipping the coin.
simulator_core.random_set
In [75]:
# Flips the biased coin N-times and returns the
# vector of results
def random_set(probability, count):
result = []
for i in range(0,count):
event = biased_coin(probability)
result.append(event)
return result
/tests/unit_test_sequence
- We will run a simple "eyeball test" to see if the sequences look reasonable.
- We will also test the average behavior.
In [77]:
def eyeball_event_str():
event_stream = random_set(0.333,20)
print("Event stream = ", event_stream)
def test_event_string_avg():
event_stream = random_set(0.333, 10000)
count = len(event_stream)
total = 0
for i in range(0, count):
total = total + event_stream[i]
avg = total / count
print("test_event_string: avg = ", avg, " element count = ", count)
eyeball_event_str()
test_event_string_avg()
Compute Slumps¶
- Simulate a season of at-bats with _randomset()
- Process the season and find the hitless streaks.
simulator_core.failure_streak_lengths
- My typing and debugging the code while you watch is tedious.
- Instead I will step through and comment the code to explain the logic.
In [83]:
def failure_streak_lengths(event_stream):
result = []
on_a_streak = False;
count = len(event_stream)
on_a_streak = False
current_fail_streak = 0
for i in range(0,count):
current_event = event_stream[i]
if current_event == 0:
if on_a_streak == False:
on_a_streak = True
current_fail_streak = 1
else:
current_fail_streak = current_fail_streak + 1
else:
if on_a_streak == True:
on_a_streak = False;
result.append(current_fail_streak)
current_fail_streak = 0
else:
if on_a_streak == True:
result.append(current_fail_streak)
return result
/tests/unit_test_length
In [85]:
def eyeball_streak_length():
event_stream = random_set(0.333, 30)
print("Event stream = ", event_stream)
fail_streaks = failure_streak_lengths(event_stream)
print("Hitless streaks = ", fail_streaks)
eyeball_streak_length()
Slumps per Season¶
- Well, I can find the individual hitless streaks.
- What I want is the distribution or histogram of the hitless streak lengths/season.
- There is nothing special about "baseball hitless streaks," and I will just continue to use my various biased coin functions.
simulator_core.histogram_streak_lengths
In [87]:
def histogram_streak_lengths(lengths):
result = []
max_fails = max(lengths)
for j in range(0,max_fails+1):
result.append(0)
for i in range(0,len(lengths)):
fails = lengths[i]
result[fails] = result[fails] + 1
return result
/tests/test_histogram
In [88]:
def eyeball_histogram():
event_stream = random_set(0.250, 30)
print("Event stream = ", event_stream)
fail_streaks = failure_streak_lengths(event_stream)
print("Streaks = ", fail_streaks)
fail_histo = histogram_streak_lengths(fail_streaks)
print("Histogram = ", fail_histo)
eyeball_histogram()
Status Check¶
- I can now simulate a season and report on number of streaks of a given length.
- There are about 600 at-bats in a season.
In [92]:
def simulate_season(avg, no_at_bats):
event_stream = random_set(avg, no_at_bats)
fail_streaks = failure_streak_lengths(event_stream)
fail_histo = histogram_streak_lengths(fail_streaks)
return fail_histo
ab = 600
avg = 0.250
print("Simulating seasons with ", ab, "at bats and batting average ", avg)
histo = simulate_season(avg, ab)
for i in range(0,len(histo)):
print("Streak length ", i, " no of occurences ", histo[i])
In [ ]:
import matplotlib.pyplot as plt
def add_to_plot(x,y):
result = False
if (isinstance(x,int) or isinstance(x,float)) and \
(isinstance(y,int) or isinstance(y,float)):
plt.plot(x,y,"ro")
result = True
return result
In [98]:
for i in range(0,len(histo)):
add_to_plot(i,histo[i])
plt.title("No of streaks.")
plt.xlabel("Streak length")
plt.ylabel("No. of streaks of length")
plt.show()
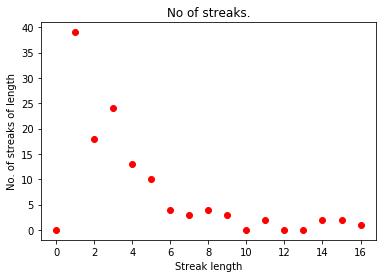
Next Steps¶
- Simulate many seasons.
- Aggregating each season allows me to compute the expected number of hitless streaks of length n per season.
- Then can determine if slumps really occur, or are just part of statistical behavior.